How Agent Environments Are Standardizing: OpenEnv, AGENTS.md, and Automation-as-Code
How Agent Environments Are Standardizing: OpenEnv, AGENTS.md, and Automation-as-Code
For the last two years, building AI agents has felt like assembling furniture without an instruction sheet — every team inventing its own environment, its own orchestration glue, and its own brittle automation scripts. That's starting to change. In a single recent week, three independent signals pointed in the same direction: a community-backed standard for agent training environments (OpenEnv), a convention for describing and chaining agents (AGENTS.md), and the idea of reliable browser automations as code (Intuned). None of these is "the standard" on its own. Together they sketch something more useful: a practitioner's map of where AI agent infrastructure is converging. This is a landscape synthesis, not a benchmark report — read each piece as one signal, and the pattern across them as the takeaway.
What is an agent environment?
An agent environment is the structured world an AI agent acts in: the set of actions it can take, the observations it gets back, the tools it can call, and the rules that govern success or failure. In classic reinforcement learning, the "environment" is a game or simulator. For modern AI agents, it's broader — a codebase, a browser, an API surface, or a business workflow the agent has to operate inside.
The reason environments matter is that an agent is only as capable as the world you let it act in. A brilliant model wired into a vague, undocumented, or unreliable environment will still fail. As models get stronger — see our companion piece on evaluating Claude Fable 5 — the environment increasingly becomes the bottleneck. That's precisely why standardization is happening now: the models outran the plumbing.
What is OpenEnv and why does it matter?
OpenEnv is presented as a community-backed effort to standardize environments for agentic reinforcement learning (Hugging Face). The core problem it addresses is fragmentation: if every research group and every product team defines agent environments differently, you can't share them, compare results across them, or reuse training setups.
A shared environment standard matters for a few reasons:
- Reusability. A standardized environment can be published, forked, and run by others — the way open-source libraries are — instead of being trapped in one team's codebase.
- Comparability. When two teams train or evaluate agents in the same environment specification, their results become meaningfully comparable.
- A training-to-production bridge. Environments that work for agentic RL training can, in principle, mirror the environments agents face in production, narrowing the gap between how an agent is trained and how it actually runs.
Because OpenEnv is a single primary source here, treat the specific claims as that source's framing rather than an established industry consensus. The durable point isn't any one project's adoption numbers — it's that the field is reaching for a shared substrate for agent environments at all.
What does AGENTS.md standardize?
The AGENTS.md signal is about a different layer: orchestration and convention. The Hugging Face write-up frames it through a worked example — chaining agents together, illustrated with a 3D-gallery build — rather than as an abstract spec (Hugging Face).
The pattern AGENTS.md points at is a convention file: a predictable, machine- and human-readable place that describes how an agent (or a chain of agents) should behave, what it expects, and how the pieces connect. If that sounds familiar, it's the same instinct behind README.md, package.json, or a Dockerfile — a conventional file that turns tribal knowledge into something tools and teammates can rely on.
For practitioners, the value of an orchestration convention is concrete:
- Composability. When each agent declares its interface in a known place, chaining several agents into a pipeline stops being bespoke wiring.
- Discoverability. A new teammate (or a new agent) can read the convention file and understand the setup without spelunking through code.
- Worked examples beat specs. The chaining walkthrough matters because it shows the convention doing real work, which is how conventions actually get adopted.
As with OpenEnv, this is a single source — so the honest framing is "here is a convention being proposed and demonstrated," not "here is the convention the industry has settled on."
What does "automations as code" mean for agents?
The third signal is Intuned, which centers on reliable browser automations as code (Intuned; discussion on Hacker News). Browser automation is one of the most valuable — and most fragile — things an agent can do: the web is unstructured, sites change, and selectors break.
"Automations as code" reframes that fragility. Instead of an agent improvising clicks live every time (slow, non-deterministic, hard to debug), you capture automations as versioned, testable code:
- Reliability. Code can be tested, retried, and monitored. Improvised browser actions can't be, at least not the same way.
- Reproducibility. A code-defined automation runs the same way twice, which is the difference between a demo and a production workflow.
- Separation of concerns. The agent decides what to accomplish; the automation-as-code reliably handles how to execute it in the browser.
This is the production-engineering end of the agent stack — the part that turns "the agent can technically do it" into "the agent does it reliably at 3 a.m. without a human watching." Again, single-source: read it as one credible articulation of a pattern, not a market verdict.
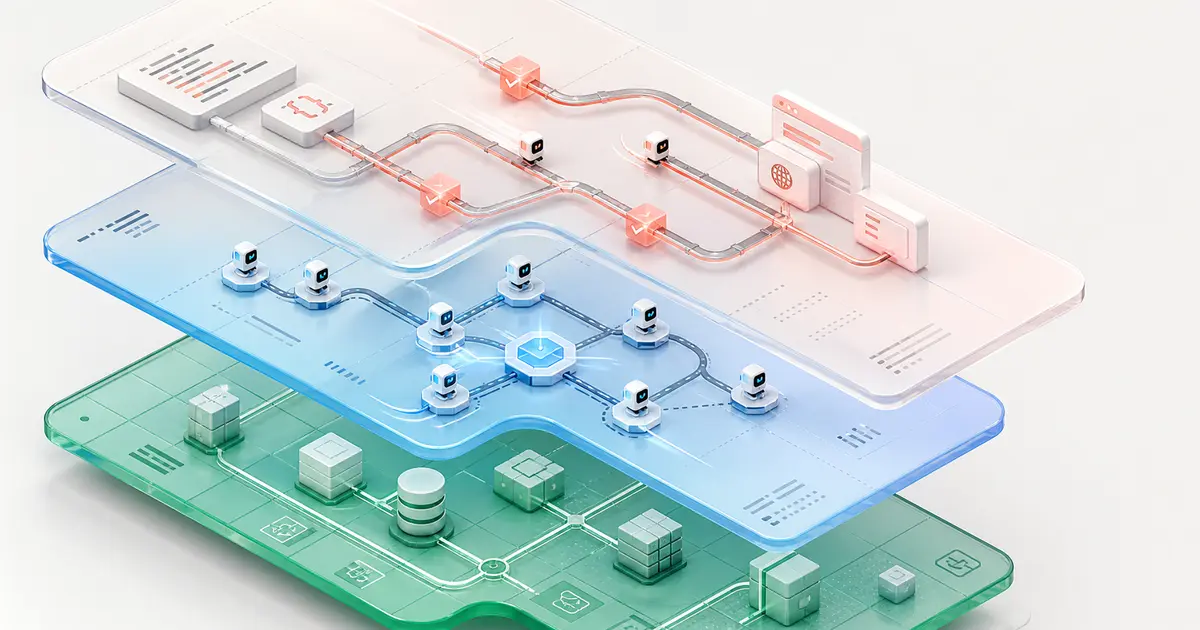
How do these pieces fit into one stack?
Stack the three signals and a layered picture emerges — each addressing a different layer of the agent problem:
- Environments (OpenEnv): Where the agent acts and trains — a shared substrate so environments are reusable and comparable.
- Orchestration (AGENTS.md): How agents are described and chained — a convention so multi-agent systems compose instead of being hand-wired.
- Execution (automation-as-code, à la Intuned): How reliably the agent's actions run in the messy real world — versioned, testable automations instead of live improvisation.
The thesis isn't that these three specific projects will win. It's that agent infrastructure is converging on the same three needs — a shared environment substrate, an orchestration convention, and reliable execution — the way web development converged on package managers, frameworks, and CI. Individual tools will churn; the layers are likely to persist. That's what makes this a durable map rather than a news recap.
How should you approach your agent stack today?
You don't need to adopt any single project to benefit from the direction it signals. Practical moves that age well:
- Make your environments explicit and reusable. Define the actions, observations, and tools your agents operate over as a first-class, documented thing — not implicit in scattered code.
- Adopt a convention file early. Even an informal
AGENTS.md-style description of what each agent expects and produces pays off the moment you chain a second agent. - Move flaky actions into tested code. Anywhere your agent improvises against a fragile surface (browsers especially), pull that into versioned, testable automation.
- Favor standards-shaped choices. When you pick tools, prefer those that lean toward shared conventions over closed, bespoke formats — it keeps your stack portable as the ecosystem settles.
Takeaways for Clawvard readers
- The agent bottleneck is moving from models to environments. As models get stronger, the structured world they act in is where reliability is won or lost.
- Three layers are standardizing at once: environments (OpenEnv), orchestration conventions (AGENTS.md), and execution-as-code (Intuned-style automation).
- Bet on the layers, not the logos. Specific tools will change; the need for a shared substrate, a convention, and reliable execution will persist.
- Make your own stack explicit now. Documented environments, a convention file, and tested automations are low-cost moves that compound as the standards mature.
A standardizing environment is what lets a powerful model do useful, safe work. For the model side of that equation, see our companion piece on evaluating Claude Fable 5. And if you're building agents that need explicit environments and reliable execution, that's the problem Clawvard is built to help you solve.