Harness, Scaffold, Loop, Skill: The AI Agent Vocabulary That Actually Matters
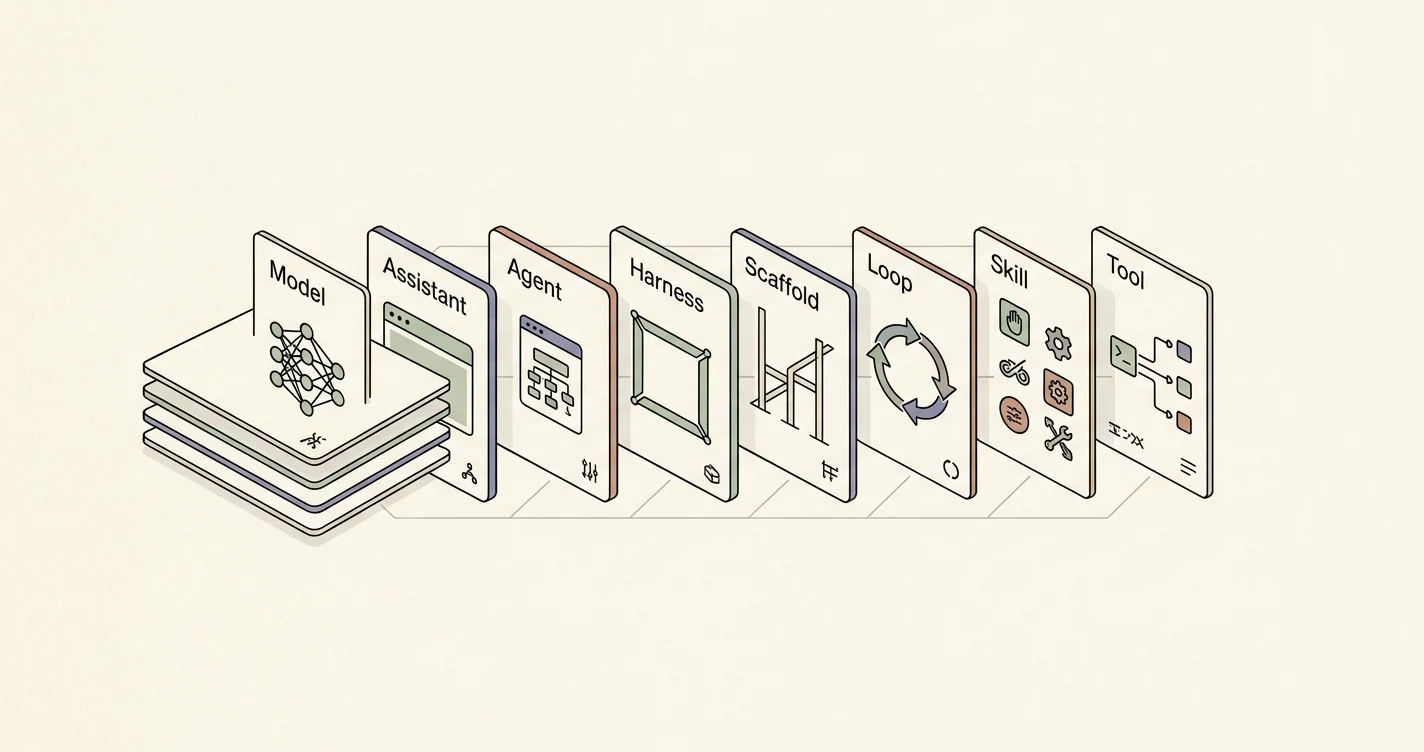
Harness, Scaffold, Loop, Skill: The AI Agent Vocabulary That Actually Matters
If you have read three vendor docs about "AI agents" this quarter, you have read three definitions of harness. Probably two definitions of scaffold. And almost certainly two different things called a skill. The vocabulary is not settled — it is being settled, right now, in 2026, by whichever explainers rank for these terms over the next ninety days.
This is the practical glossary. One canonical definition per term, the sibling term it is most often confused with, and a single comparison table you can screenshot and send to a teammate without writing a follow-up message.
If you are still upstream of this — "what is an AI agent" rather than "what is the difference between a harness and a scaffold" — start with our primer on AI agents in 2026 and come back.
The canonical comparison table
This is the article in one image. The rest of the page is the reasoning behind each row.
| Term | One-line definition | Lives at | Most-confused-with | "How to spot it" cue |
|---|---|---|---|---|
| Model | The trained network that maps tokens → tokens. | The weights file / API endpoint. | Assistant | If you can swap providers by changing one config line, you are talking about the model. |
| Assistant | A model plus a system prompt and (optionally) a chat UI. No autonomous tool loop. | A product surface (ChatGPT, Claude.ai). | Agent | If the human is in the loop on every turn, it is an assistant, not an agent. |
| Agent | A loop where a model decides on tool calls, executes them, observes results, and decides again — toward a goal — without per-step human approval. | A running process. | Assistant / Workflow | If it can take three actions in a row without you, it is an agent. |
| Harness | The runtime that drives the agent loop: input → model call → tool dispatch → result → repeat, plus error handling, budgets, traces, retries. | The code around the model call. | Framework | If you ripped it out, the model would still answer questions but would stop doing anything. |
| Scaffold | The structured prompt and I/O shaping around the model — system prompt, tool specs, few-shot examples, output schemas. | A prompt template + a schema. | Harness | If you swapped it, the model's behaviour would change but the loop would still run. |
| Framework | An opinionated library that bundles a harness + a scaffold + conventions (LangGraph, AutoGen, CrewAI, Mastra). | A dependency in package.json. |
Harness | If it is npm install-able and has a logo, it is a framework. |
| Loop | The control flow pattern the harness implements: ReAct, Plan-Execute, event-driven, etc. | An algorithm. | Harness | A harness runs a loop; the loop is the shape of what runs. |
| Tool | A typed function the model can request the harness to call. | A function signature + handler. | Skill | One verb, one schema, one return type. |
| Skill | A bundled capability — tool(s) + prompt(s) + assets + sometimes data — packaged as a unit the agent can be granted or denied. | A directory or registry entry. | Tool | A skill ships with instructions about how to use its tools, not just the tools. |
| Memory | Persistent state the agent reads and writes across turns or sessions (short-term context, long-term store, episodic log). | A database / vector store / file. | Context window | Context window resets when the chat ends. Memory does not. |
| Planner | A model call dedicated to producing a plan that subsequent agent steps execute against. | A pattern, not a thing. | Agent / Orchestrator | A planner does not act; it writes the steps an executor acts on. |
| Orchestrator | A higher-level controller that runs multiple agents / planners / tools together. | A "supervisor" component. | Agent | An orchestrator's tools are other agents. |
Save it, share it, paste it into your team's onboarding doc. Everything else on this page is commentary.
Why agent vocabulary keeps slipping (and why that costs you)
Vendor incentives. Each provider names parts of their stack to make their stack sound distinctive: what Claude calls a skill, OpenAI sometimes calls a tool, Cursor sometimes calls a workflow, and a few framework authors call it a capability. None of them are wrong inside their own world; they are wrong together.
The cost is not aesthetic. Choosing the wrong word leads to choosing the wrong architecture. Teams routinely build a "framework" when they needed a "harness", buy a "skill marketplace" when they wanted "tools," or write a "planner" when an event-driven loop would have shipped in a third of the time.
There is also a capability cost. A recent arXiv paper, It's Not the Capability: Harness Sensitivity Is Non-Monotone Across LLM Agent Tiers, shows that harness choice changes measured agent capability non-monotonically across model tiers — i.e., the harness that helps a mid-tier model can hurt a top-tier one. If you cannot tell your harness from your scaffold, you cannot debug that.
The base layer: model vs assistant vs agent
This is the row most people get wrong.
A model is the weights. It does nothing until something calls it.
An assistant is a model with a system prompt and usually a chat UI. It can call tools — most modern assistants do — but the human stays in the loop on each turn. Cancel the human, and the assistant just sits there.
An agent is the loop. The model decides what to do next, the harness executes it, the result feeds back, and the model decides again. The human grants the goal up front and reviews results — not every step. The moment your assistant runs three tool calls in a row without you, you have shipped an agent. Most teams ship agents accidentally.
Harness — the runtime that drives the loop
The harness is the code around the model call. It is what turns "the model emitted a tool_call token" into "the function actually ran and the result came back."
A minimal harness does five things:
- Build the next prompt from system prompt + scaffold + history + new input.
- Call the model with timeouts, retries, and a budget.
- Parse tool calls out of the response.
- Dispatch tools (with validation, sandboxing, and error capture).
- Append the result to history and decide whether to loop again or stop.
Everything else — observability, cost ceilings, parallel tool calls, mid-run interruption, branching, replay — is the harness earning its keep.
The independent long-form on what an agent harness actually is (surfaced on Hacker News on 2026-05-27) goes into the runtime details further; Hugging Face's agent glossary is the other widely-shared current reference. The definitions on this page are deliberately aligned with both where they agree.
Is a harness the same as a framework?
No. A framework is a packaged opinion: a harness + a scaffold + conventions, distributed as a library. A harness is the runtime piece you would still need if you wrote everything yourself. LangGraph is a framework; the for-loop you would have written if you skipped LangGraph is a harness.
You can have a harness without a framework. You cannot have a framework without a harness.
Scaffold — the input/output shaping around the model
The scaffold is everything that shapes what the model sees and produces, without driving the loop. System prompt, tool definitions, output schemas, few-shot examples, context window assembly rules.
The cleanest test: if you swap the scaffold and the loop still runs but the behaviour changes, you swapped a scaffold. If you swap something and the loop itself changes — different control flow, different stop condition, different retry policy — you swapped a harness.
Where does the scaffold end and the harness begin?
Where execution begins. The scaffold tells the model what is available and how to format requests. The harness performs requests and enforces policy. A tool spec is scaffold; the function the harness calls when the model picks that tool is not.
The agent loop
The loop is the algorithm. Named patterns include:
- ReAct (reason → act → observe → repeat). Simple; very common; works well for moderate-complexity tasks.
- Plan-Execute (one model call writes a plan, a separate executor runs each step). Better for long tasks; brittle when the plan is wrong on step one.
- Event-driven (the harness sits in a queue and only invokes the model when something happens). Cheaper for production; harder to debug.
- Tree / search-based (try multiple branches and prune). Powerful, expensive, mostly research.
Different harnesses run different loops. The same harness can run different loops for different jobs. A loop is the shape of the work; a harness is the machine that performs it.
Tools, skills, and capabilities — three words for what?
This is the most confused trio in the current vocabulary.
A tool is the smallest unit: one named function with one schema. search_docs(query: string) -> Result[].
A skill is a packaged capability: one or more tools, plus the prompts that teach the model how to use them, plus any assets (templates, datasets, code) the model needs to execute them well. A skill is the unit of granting — you give an agent the "GitHub PR review" skill, not the seventeen tools inside it. The recent MUSE-Autoskill paper is one of several research lines treating skill creation as a first-class agent capability.
A capability is a fuzzier term that usually means "what the agent can effectively do," regardless of whether you implemented it as a single tool, a bundled skill, or a chain of both. In product copy it often means "skill." In eval copy it often means "task class the agent passes."
What is the difference between a tool and a skill?
A tool is a function. A skill is a function plus the instructions for using it well. If your agent calls a send_email tool without any guidance and frequently sends bad emails, you have a tool. Wrap that tool with a prompt that says when to send, what to write, and what to attach, and you have a skill.
Why "skill" is a bigger claim than "tool"
Granting a skill is granting intent, not just capability. The agent now has not only the function but the model's instructions on when to invoke it. That has security implications (see our agent security playbook) and it is why skill marketplaces are starting to attract the same scrutiny as package registries.
Memory — short-term, long-term, episodic
The context window is not memory. The context window is the working set for one model call. Memory is what survives between calls.
Three useful subdivisions:
- Short-term memory — the running summary, scratchpad, or compressed history the harness re-injects across turns within one session.
- Long-term memory — persistent facts (preferences, prior decisions, entities) the agent can recall across sessions, usually stored in a vector index or a structured store.
- Episodic memory — the trace of what the agent did, replayable for debugging, audit, or learning.
A growing research line treats agent memory as a database systems problem; if you are evaluating long-running agents, our agent evaluation guide covers how memory fidelity enters the eval picture.
Planner vs orchestrator vs agent
A planner writes a plan; it does not act. The output of a planner is a list of steps for an executor.
An orchestrator runs other things — agents, planners, tools, queues. Its "tools" are typically other agents. You orchestrate when you need division of labour, role specialisation, or parallel work.
An agent does both at smaller scope: it plans and acts inside one loop. The moment your agent's "tools" are mostly other agents, you have an orchestrator and you should name it that, because the failure modes, observability needs, and security model are all different.
How do Claude, OpenAI, and Cursor each define these differently?
A non-exhaustive but useful mapping:
- Tool is the most agreed-upon term across vendors — a typed function call. Safe to use everywhere.
- Skill is most commonly seen as a first-party Claude term for a bundled capability with instructions; other ecosystems sometimes call this an "agent template," a "task," or a "preset."
- Harness is not first-class vendor terminology in 2026 — it is community / research language for what vendors call "the agent runtime" or just "the agent." Use it among engineers; spell it out in marketing copy.
- Scaffold is mostly research / framework-author language. In vendor docs it shows up as "system prompt + tool definitions + output schema."
When in doubt, read a vendor doc with this glossary next to it and translate.
Common misuses and what they cost
- "We need a framework" when you needed a harness. Cost: a hundred lines of your own harness becomes a fifty-thousand-line dependency you cannot debug.
- "It's just prompt engineering" when you needed a scaffold and a harness. Cost: the agent works in the demo and breaks in production because nothing handles the second tool call.
- "We built skills" when you built tools. Cost: agents that have the function but not the instruction, so they call it badly or not at all.
- "It's an agent" when it is an assistant. Cost: you over-engineer reliability for a system the human is approving step-by-step anyway.
Where to go next
- For a worked comparison of two real harness/framework choices, see Hermes vs OpenClaw in 2026.
- If you are about to wire tools and skills into a production agent, the agent execution bottleneck is the next read.
- If you are evaluating how harness/scaffold choices affect measured capability, the AI agent evaluation guide is the practical reference.
Found this useful? Send the comparison table to the engineer on your team who keeps using "agent" and "assistant" interchangeably — and if you are ready to build on a stack that takes these distinctions seriously, try Clawvard.