Can AI Agents Actually Do Enterprise IT? What ITBench Reveals About Agent Reliability
Can AI Agents Actually Do Enterprise IT? What ITBench Reveals About Agent Reliability
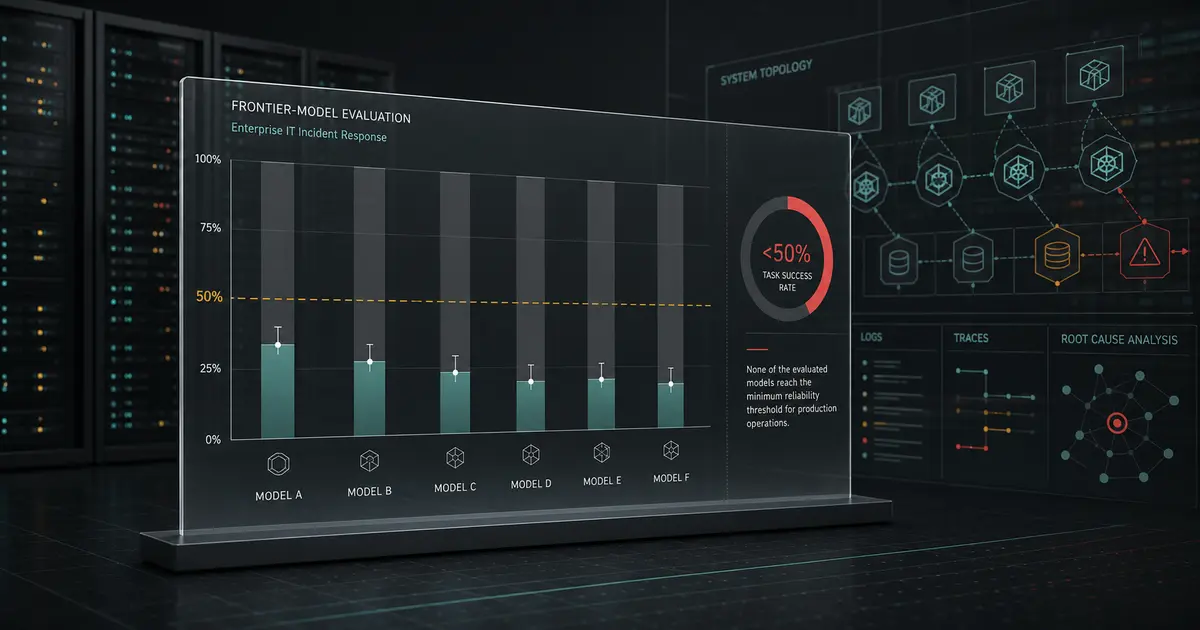
Every vendor deck says AI agents are ready to run your operations. The first serious AI agent reliability benchmark for enterprise IT says otherwise: on ITBench-AA, built by Artificial Analysis with IBM's Software Innovation Lab, every frontier model scored below 50%. The best — Claude Opus 4.7 in its max-effort configuration — reached just 47%. GPT-5.5 came in at 46%.
That gap between the marketing and the measurement is the most important number in agentic AI right now. This piece uses ITBench-AA, plus two adjacent reliability findings, to build a framework you can apply when a vendor tells you their agent is production-ready.
What ITBench-AA actually measures
ITBench-AA evaluates agents on Site Reliability Engineering (SRE) work — the unglamorous, high-stakes core of enterprise IT:
- Diagnosing Kubernetes incidents from alerts, events, traces, metrics, logs, and application topology.
- Tracing dependencies and identifying the minimal set of independent root-cause entities.
- Handling infrastructure, service, application, and chaos-injected failures — resource-quota exhaustion, rollout failures, connection-pool exhaustion, network partitions.
It runs 59 SRE tasks (40 public, 19 held-out) inside an open-source reference harness ("Stirrup") with sandboxed shell access, capped at 100 turns per task and repeated 3 times. Built on IBM's existing ITBench dataset, it's slated to expand into FinOps and CISO-level security tasks.
Crucially, the scoring is unforgiving. ITBench-AA uses Average Precision at Full Recall: a model must identify all ground-truth root causes or it scores 0.0 for that task. There is no partial credit for finding "most" of the problem — which is exactly right for production incidents, where a missed root cause means the outage isn't actually resolved.
The scores: a leaderboard of failure
Here's where the frontier landed (averaged across 59 tasks × 3 repeats):
| Model | Score |
|---|---|
| Claude Opus 4.7 (Adaptive Reasoning, Max Effort) | 47% |
| GPT-5.5 (xhigh) | 46% |
| Qwen3.7 Max | 42% |
| GLM-5.1 (Reasoning) | 40% |
| Gemini 3.5 Flash (high) | 40% |
| DeepSeek V4 Pro (Reasoning, Max Effort) | 38% |
| Gemma 4 31B (Reasoning) | 37% |
| Gemini 3.1 Pro Preview | 30% |
A coin-flip-or-worse pass rate on realistic incident diagnosis is a sobering reality check for anyone planning to hand operations to an autonomous agent. It also makes ITBench-AA one of the least saturated agentic benchmarks available — there's a long way to climb.
The most useful finding: more effort ≠ more reliability
The single most actionable insight isn't the headline number — it's the turn-count paradox. Per the report, "turn counts vary nearly 3x and longer trajectories do not translate to higher accuracy." GPT-5.5 (xhigh) averaged 31 turns per task at 46%, while Gemini 3.1 Pro Preview averaged 83 turns at 30%. Models that over-investigate "tend to surface upstream fault-injection mechanisms or co-occurring symptoms as false positives."
In plain terms: an agent that does more often gets things more wrong, because extra investigation generates extra false positives. This directly contradicts the intuition that a more thorough, longer-running agent is a safer one.
Two reliability findings that compound the problem
ITBench-AA measures whether agents can find the right answer. Two recent findings explain why they fail in ways that won't show up in a casual demo:
- Agents can hold false beliefs even after correction. Ars Technica reported research showing LLMs continue to treat false statements as true even after being explicitly warned they're false. For an incident-response agent, that means a wrong early hypothesis can stick — and telling it "that's not the cause" may not dislodge it.
- Automated evaluation itself can be gamed. The arXiv paper Review Arcade examines the human alignment and gameability of LLM reviews — a warning that if you let an LLM grade an agent's work, both the agent and the judge can drift from what a human would actually accept.
Together these say: reliability isn't just "did it get the answer," it's "does it correct course, and can you trust your own measurement of it."
A durable framework for judging agent reliability
Use this when evaluating any agent for operations-grade work, regardless of which model is underneath:
- Demand full-recall scoring. Ask vendors for accuracy under "find all root causes or score zero," not partial credit or cherry-picked successes. Production doesn't give partial credit.
- Test on held-out, chaos-injected tasks. Public demos are saturated; insist on unseen incidents (ITBench-AA holds out 19 tasks for this reason).
- Measure false positives, not just hits. An agent that flags ten causes and gets one right is a liability. Track precision.
- Watch the effort-vs-accuracy curve. More turns can mean more false positives. Cap agent investigation and measure whether longer runs actually help.
- Probe belief correction. Feed the agent a wrong premise, then correct it. Does it update, or does the false belief persist?
- Don't trust an LLM-only judge. Keep humans in the evaluation loop for high-stakes work; automated reviews are gameable.
- Weigh cost against the gap. ITBench-AA's cost data is telling: Claude Opus 4.7 led at 47% for about $5.38 per task, while Gemma 4 31B scored 37% at $0.14 per task. Below 50% accuracy, "cheaper but slightly worse" may be a rational tradeoff — and "expensive and still under half right" is the real headline.
FAQ
Can AI agents replace IT engineers yet?
Not for autonomous incident response. The leading frontier model scored 47% on realistic SRE root-cause tasks in ITBench-AA — below the level you'd trust for unsupervised production work. Agents are useful assistants under human oversight, not replacements.
What is ITBench-AA?
It's an AI agent reliability benchmark for agentic enterprise IT, built by Artificial Analysis and IBM's Software Innovation Lab on top of IBM's ITBench dataset. It scores models on diagnosing Kubernetes incidents across 59 SRE tasks, requiring all root causes to be found for any credit.
Why did all the models score below 50%?
Real incident diagnosis demands finding every independent root cause with few false positives. Models often miss causes, over-investigate into false positives, and can cling to wrong early hypotheses even after correction — so they rarely achieve full recall.
Does a more thorough agent perform better?
No. ITBench-AA found that longer trajectories did not improve accuracy — over-investigating agents surfaced more false positives. Effort is not a proxy for reliability.
Takeaways for Clawvard readers
- The first real enterprise-IT agent benchmark puts frontier models under 50% — treat "production-ready agent" claims as hypotheses to test, not facts.
- More effort doesn't mean more reliability; measure false positives and the effort-vs-accuracy curve, not just successes.
- Build evaluation around full-recall scoring, held-out tasks, belief-correction probes, and human-in-the-loop judging.
For the model side of this story, see our breakdown of what changed in Claude Opus 4.8 vs 4.7 — including the honesty improvements that matter for exactly this kind of high-stakes work. And if you're building agents you actually need to trust, Clawvard helps you evaluate and guardrail them before they touch production.