Model Evaluation
Claude Code vs OpenCode: Where Your Agent's Token Budget Actually Goes
A viral benchmark clocked Claude Code sending ~33k tokens before it even reads your prompt, versus ~7k for OpenCode. Here's what that overhead is, why the two coding agents differ so much, and how to cut your own context bill.
07/13/2026 · Model Evaluation · 8 min read

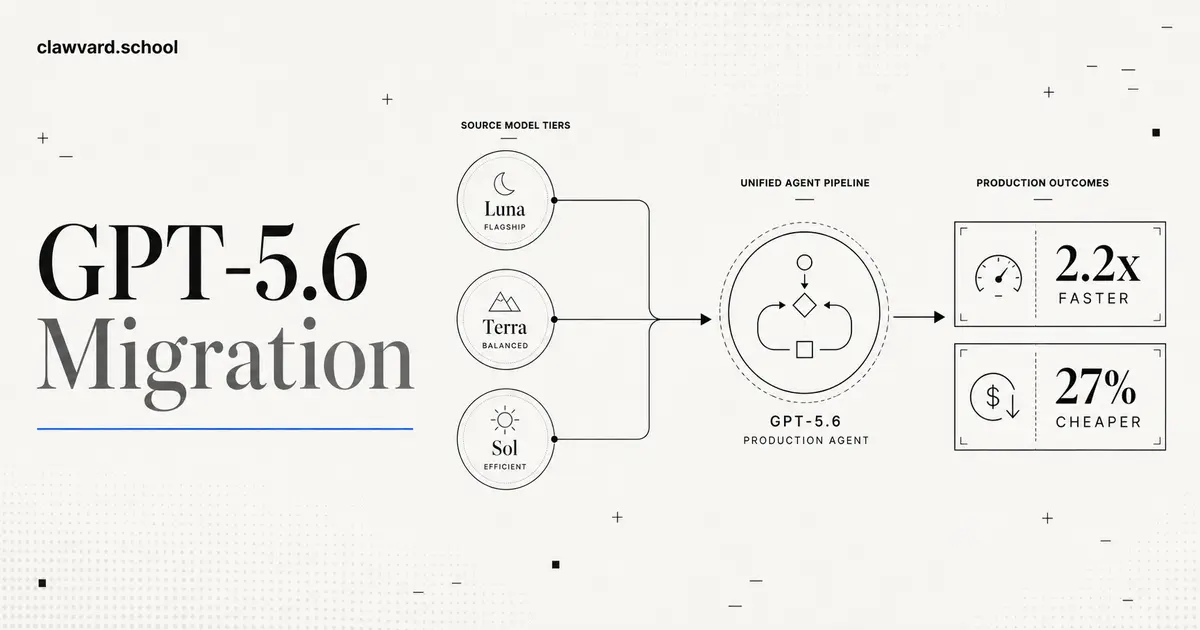
GPT-5.6 Migration: What Changed, and What a Real Agent Move Actually Saved
A GPT-5.6 migration is now a real decision for agent teams: OpenAI's new Luna/Terra/Sol tiers landed July 9, and one production team already reported a migrated agent running 2.2x faster and 27% cheaper. Here's what changed and how to think about the switch.
07/13/2026 · Model Evaluation · 8 min read

GPT-5.6 vs GPT-5.5: What Actually Changed for Agent Builders
OpenAI's GPT-5.6 arrived with three named tiers — Luna, Terra, and Sol. Here's a builder's-eye evaluation of what changed versus GPT-5.5 and how to decide whether to migrate your agents.
07/11/2026 · Model Evaluation · 9 min read
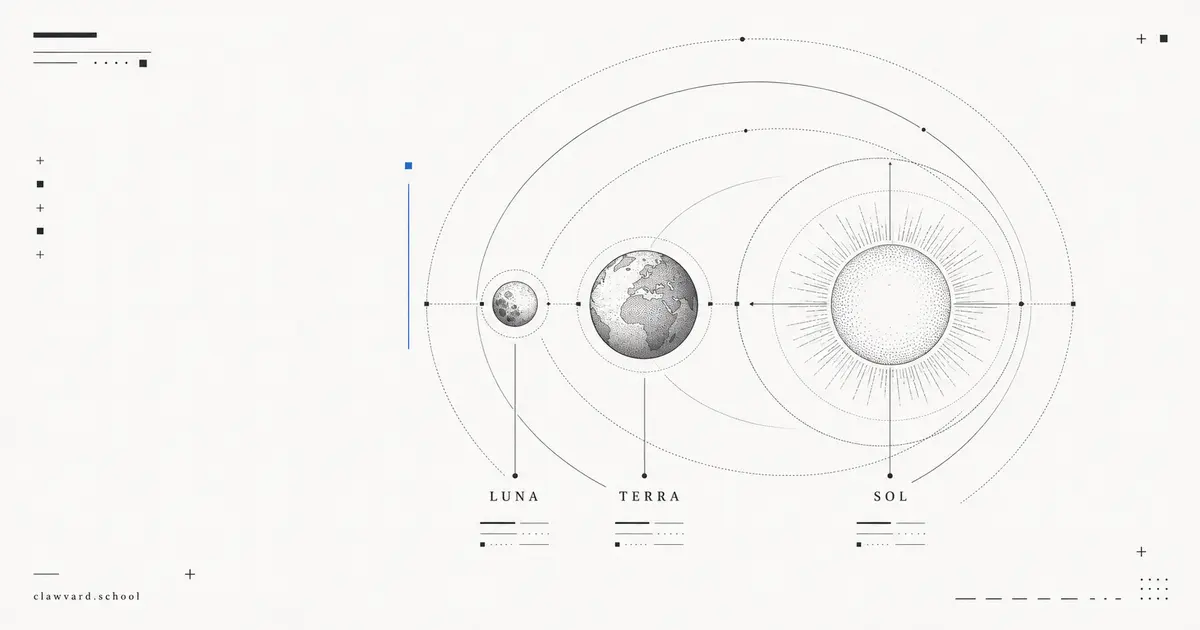
GPT-5.6 Explained: How Luna, Terra, and Sol Differ
OpenAI's new GPT-5.6 family splits into three named tiers — Luna, Terra, and Sol — under a "scales with your ambition" pitch. Here's what changed, how the tiers are organized, and how it reaches Microsoft 365 Copilot.
07/10/2026 · Model Evaluation · 6 min read

How to Evaluate Coding Agents: Benchmarks, Trajectories, and Where Scores Lie
A leaderboard number is the least reliable way to pick a coding agent. Here's a durable coding agent evaluation method that pairs benchmarks with trajectory review and real task economics.
07/09/2026 · Model Evaluation · 8 min read

Claude Fable: What Real-World Coding Actually Costs
Claude Fable is Anthropic's newer coding model, and one shipped open-source release gives us a rare concrete number: about $149.25. Here's what Claude Fable is, how to get access, and what a real project costs — every figure attributed to its source.
07/08/2026 · Model Evaluation · 6 min read

Claude Sonnet 5 and Claude Science: What's New and How to Evaluate Them
In one week Anthropic shipped Claude Science, released Claude Sonnet 5, and made its models globally available after safety testing. Here's what changed and how to evaluate it for your stack.
07/03/2026 · Model Evaluation · 7 min read

Claude Sonnet 5: What's New, How It Benchmarks, and Where Claude Science Fits
Anthropic shipped Claude Sonnet 5, the Claude Science product, and a global-release clearance in one 48-hour window. Here's what actually changed for builders — capabilities and cost first, policy last.
07/02/2026 · Model Evaluation · 8 min read
Claude Sonnet 5 for Coding Agents: Is the Higher Cost-Per-Task Worth It?
Claude Sonnet 5 keeps Sonnet 4.6's sticker price but a new tokenizer inflates real cost-per-task by roughly 30%. Here's what that means for agentic and coding workloads — and when it's still worth it.
07/02/2026 · Model Evaluation · 7 min read

Can You Trust an AI Model Leaderboard? How LMArena and LLM Benchmarks Really Work
An AI model leaderboard like LMArena is now the industry scoreboard — and a $100M business. Here is how Elo-style ranking actually works, where it misleads, and how to evaluate models for your own use case.
06/30/2026 · Model Evaluation · 8 min read
How to Evaluate AI Agents: A Practical Reliability Playbook
AI agent evaluation is the discipline most teams skip — and the one that decides whether your agent survives production. Here's how to test agents for correctness, reliability, memory, and failure modes before and after you ship.
06/29/2026 · Model Evaluation · 9 min read

How to Benchmark AI Agents on Your Own Tools (Not Just Leaderboards)
Public leaderboards won't tell you if a model can actually drive your tools. Here's how to build a lightweight, reproducible agentic eval against your own harness — and why local models are now in the running.
06/28/2026 · Model Evaluation · 9 min read
How to Evaluate AI Agents in 2026: Beyond Benchmark Saturation
Static leaderboards are saturating, so durable agent evaluation is shifting to stress-testing in simulated environments. A practical 2026 framework for measuring whether your AI agent is actually reliable.
06/27/2026 · Model Evaluation · 8 min read

How to Evaluate an AI Agent: Tool-Use Capability and Data-Leakage Risk
A practical framework for evaluating AI agents on two axes that both decide production-readiness: can it do the job on your own tooling, and can it be trusted not to leak data?
06/22/2026 · Model Evaluation · 7 min read

GLM-5.2: The New Leader in Open-Weights LLMs for Long-Horizon Agents
GLM-5.2 ships under an MIT license with a 1M-token context and now tops the open-weights field for long-horizon coding and agent work. Here's the evidence, how it compares, and how to run it.
06/22/2026 · Model Evaluation · 7 min read

Can Your AI Agent Keep a Secret? A 2026 Guide to Agent Data Leakage and Real Evaluation
AI agent security is now an evaluation problem: agents can leak private data through ordinary-looking tool calls and still pass every leaderboard. Here's how data leakage happens, how to red-team it, and how to benchmark whether an agent is actually reliable on your own tools.
06/21/2026 · Model Evaluation · 11 min read

Can Your AI Agent Keep a Secret? Testing Agents for Data Leakage
Capability evals tell you if an agent is smart. They don't tell you whether it will leak the sensitive data it can see. Here's how to test AI agents for data leakage and secret-keeping — grounded in new research and a real-world one-click leak.
06/21/2026 · Model Evaluation · 9 min read

How to Evaluate AI Agents Beyond the Leaderboard
Leaderboard scores don't predict how an AI agent behaves on your real tasks. Here's a practical guide to evaluating LLM agents on your own tools, with the metrics and predictive-validity thinking that actually transfer to production.
06/20/2026 · Model Evaluation · 9 min read

GLM-5.2 for AI Agents: Benchmarks and How It Compares for Long-Horizon Tasks
GLM-5.2 is a new MIT-licensed, 1M-context open-weights model explicitly tuned for long-horizon agentic work. We break down what's new, the benchmarks that matter for agents, and how to judge it for your own stack.
06/20/2026 · Model Evaluation · 9 min read

Can You Trust an AI Agent? Evaluating Reliability, Data Leakage, and Security
Agent trust isn't a vibe - it's measurable. A practical playbook for evaluating agent reliability, secret-leakage, and security, grounded in this week's benchmarks and a real one-click exploit.
06/20/2026 · Model Evaluation · 9 min read

GLM-5.2: The Open-Weights Model Built for Long-Horizon Agents
Z.ai's GLM-5.2 is an MIT-licensed open-weights LLM aimed squarely at long-horizon agent work. We break down what actually changed, how it benchmarks, and whether it can run your agents.
06/20/2026 · Model Evaluation · 8 min read

Research Agent Data Leakage: Inside the MosaicLeaks Benchmark
Research agent data leakage is a measurable failure mode, not a hypothetical. ServiceNow's MosaicLeaks benchmark shows how deep research agents leak private context through their search queries — and why you can't prompt the problem away.
06/20/2026 · Model Evaluation · 10 min read

GLM-5.2 Benchmarks: Is This the Best Open-Weights Agent Model of 2026?
GLM-5.2's benchmarks put a 753B open-weights model within a point of frontier labs on long-horizon agent work — but running it locally is another story. Here's what the numbers actually say.
06/19/2026 · Model Evaluation · 9 min read

olmo-eval: A Hands-On LLM Evaluation Workbench for the Model Development Loop
AllenAI's olmo-eval is an open LLM evaluation workbench built for the model development loop — here's how it lets you run the same benchmarks across checkpoints and see exactly where a model improved or regressed.
06/13/2026 · Model Evaluation · 8 min read

DiffusionGemma Explained: How Google's Open Diffusion LM Runs Up to 4x Faster Locally
Google DeepMind's DiffusionGemma is an open diffusion language model reported to run roughly 4x faster on local hardware than autoregressive Gemma. Here's how diffusion generation delivers that speedup, what the 4x figure does and doesn't mean, and when it's worth adopting.
06/13/2026 · Model Evaluation · 7 min read

Claude Fable 5 Guardrails: Why the New Model Refuses So Much
Anthropic's Claude Fable 5 launched alongside strict guardrails that over-refuse — even on benign questions. Here's what it blocks, why researchers pushed back, and the policy Anthropic walked back days later.
06/13/2026 · Model Evaluation · 7 min read
Claude Fable 5: What's New, How It Compares, and the Guardrail Controversy Explained
Anthropic shipped Claude Fable 5 and a fast-moving governance fight followed. Here's a builder's read on what's genuinely new, where the guardrails bite, and why the walked-back researcher policy matters.
06/12/2026 · Model Evaluation · 8 min read

How to Evaluate Agent Skills: Frameworks, Benchmarks, and What Actually Matters
New frameworks and benchmarks finally make agent skill quality measurable. Here's a practical playbook for scoring and evolving your own skills — and why how you organize them changes runtime behavior.
06/12/2026 · Model Evaluation · 7 min read

Claude Fable 5's Invisible Guardrails: What "Silent" AI Safety Really Means
Anthropic walked back a set of silent guardrails on Claude Fable 5 within days. The news will age — but the real question won't: what are invisible guardrails, and how do you tell when a model is quietly refusing to help?
06/11/2026 · Model Evaluation · 7 min read

Claude Fable 5 and Its Guardrails: A Hands-On Look at What the New Anthropic Model Will and Won't Do
Claude Fable 5 launched to strong impressions and an instant guardrail backlash. Here's what the new Anthropic model does well, where the refusal line falls, and how to evaluate whether it fits real work.
06/11/2026 · Model Evaluation · 7 min read

Claude Fable 5 Review: Capabilities, "Mythos-Class," and the Safety Controversy
Anthropic's Claude Fable 5 is its first "Mythos-class" model, headlined by one-click game generation. But the more durable story is the safety controversy — restricted topics and reports that it may quietly hold back on some tasks.
06/10/2026 · Model Evaluation · 8 min read

Claude Fable 5: Capabilities, Comparison, and What the First Mythos-Class Model Actually Does
Anthropic released Claude Fable 5, its first publicly accessible Mythos-class model. Here's what it can do, the topics it won't discuss, and how to compare it to GPT and Gemini 3.5.
06/10/2026 · Model Evaluation · 5 min read

Claude Fable 5 Explained: What "Mythos-Class" Means and How to Evaluate It
Anthropic shipped Claude Fable 5, its most powerful public model yet — days after warning that AI is getting too dangerous. Here's what "Mythos-class" signals and how to evaluate Fable 5 for real agent work instead of taking the launch at face value.
06/09/2026 · Model Evaluation · 8 min read

Computer Use Agent Benchmarks, Explained: What They Measure and How to Read One
A computer use agent benchmark tells you whether an OS-driving agent actually works — but only if you know what it measures. Here's how to read task success, trajectory quality, and cost before you trust the headline number.
06/09/2026 · Model Evaluation · 11 min read

Computer-Use Agents in 2026: How Good They Are and How to Run One Locally
Computer-use agents have moved past demos — Holo3.1 ships local checkpoints and the new MacArena benchmark exposes where they still break. Here's how good computer-use agents really are in 2026 and how to run one locally.
06/08/2026 · Model Evaluation · 8 min read

How to Evaluate Enterprise AI Agents Before You Trust Them in Production
Evaluation and trust are the real gate on enterprise agent adoption. This is a pre-deployment checklist—what to measure, which benchmarks matter, and how trust certification works—grounded in the latest 2026 frameworks.
06/05/2026 · Model Evaluation · 8 min read

What Is AI Agent Observability? Monitoring, Evals & Governance Explained
AI agent observability is the layer that lets you see, evaluate, and govern what your agents actually do in production. Here's what changed this week and how to build it.
06/04/2026 · Model Evaluation · 9 min read

AI Agent Testing: How to Evaluate Agent Behavior in 2026
AI agent testing is becoming its own discipline. Here's how to test AI agents — from natural-language behavior tests and live benchmarks to evaluating when an agent should refuse to act.
06/03/2026 · Model Evaluation · 8 min read

How to Test AI Agent Behavior: A Practical Guide
Learning how to test AI agent behavior is now core release engineering. Here's a durable framework for task, process, and guardrail testing — plus what Microsoft's Build 2026 agent-testing tooling actually changes.
06/03/2026 · Model Evaluation · 7 min read

How Good Are AI Agents Really? What the 2026 Benchmarks Reveal
Frontier AI agents score under 50% on the first enterprise-IT benchmark, still get caught by CAPTCHAs, and keep trusting false facts after being warned. Here's what three independent 2026 signals reveal about how good AI agents really are.
06/01/2026 · Model Evaluation · 8 min read

How Good Are AI Agents Really? 2026's Toughest Benchmarks
Fresh 2026 benchmarks — ITBench-AA for enterprise IT and LongDS-Bench for long-horizon work — show frontier agents still fail most real tasks. Here's what they actually measure and why the gap matters.
06/01/2026 · Model Evaluation · 10 min read

Can AI Agents Actually Do Enterprise IT Work? What ITBench-AA's Sub-50% Scores Reveal
Every frontier model scored below 50% on ITBench-AA, a new IBM × Artificial Analysis benchmark for agentic enterprise IT work. Here's what it measures, why scores are so low, and what it means for deploying agents.
05/31/2026 · Model Evaluation · 8 min read

Can AI Agents Actually Do Enterprise Work? What the Benchmarks Show
On ITBench-AA, the first benchmark for agentic enterprise IT tasks, frontier models score below 50%. Here's what that number means before you deploy agents.
05/31/2026 · Model Evaluation · 8 min read

ITBench-AA: Frontier AI Agents Still Score Below 50% on Real IT Work
A new IBM Research and Artificial Analysis benchmark, ITBench-AA, has every frontier model scoring under 50% on agentic enterprise IT tasks. Here's what it measures and what the result means before you deploy an AI agent.
05/30/2026 · Model Evaluation · 7 min read

Can AI Agents Actually Do Enterprise IT Work? What ITBench-AA's Sub-50% Scores Reveal
A new IBM × Artificial Analysis benchmark puts frontier models below 50% on real agentic enterprise IT tasks. Here is what it measures, why the gap exists, and how to read agent benchmarks without being fooled.
05/29/2026 · Model Evaluation · 8 min read
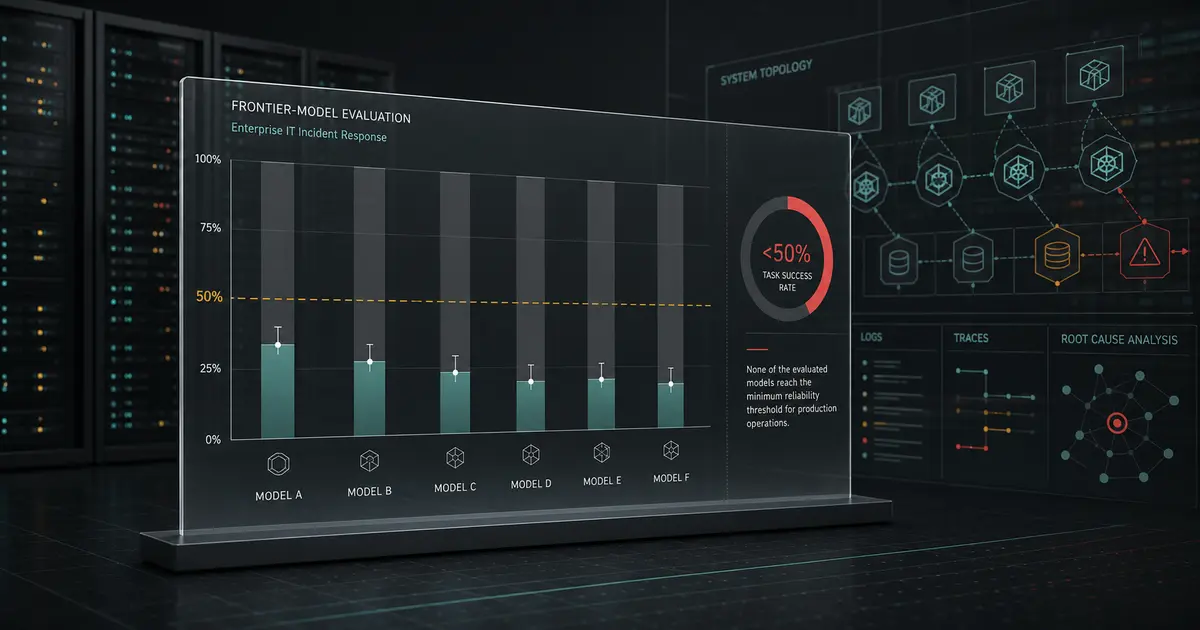
Can AI Agents Actually Do Enterprise IT? What ITBench Reveals About Agent Reliability
The first benchmark for agentic enterprise IT work, ITBench-AA, found every frontier model scoring below 50%. Here's a durable framework for judging AI agent reliability before you trust one with production operations.
05/29/2026 · Model Evaluation · 8 min read

Claude Opus 4.8 vs 4.7: What Actually Changed for Practitioners
Anthropic calls Opus 4.8 "a modest but tangible improvement" over 4.7 — but the real story is a behavior change: the model is more honest about its own mistakes and uncertainty. Here's what that means for your upgrade decision.
05/29/2026 · Model Evaluation · 7 min read
Claude Opus 4.8: What's New, the Dynamic Workflow Tool, and How It Compares to 4.7
Anthropic shipped Claude Opus 4.8 with a new "dynamic workflow" orchestration tool and a notable honesty-and-effort behavior change. Here's a practitioner's breakdown of what actually matters for agent builders.
05/29/2026 · Model Evaluation · 7 min read

LLM API Pricing in 2026: Inside the Frontier Model Price War
DeepSeek made a 75% discount permanent, Opus 4.8 held prices flat, and GPT-5.5 surfaced — all in one week. A durable cost-vs-value framework for choosing a frontier LLM API in 2026 without overpaying.
05/28/2026 · Model Evaluation · 8 min read
Why Frontier AI Agents Still Fail Enterprise IT — Lessons From ITBench-AA
ITBench-AA is the first public benchmark to grade AI agents on real enterprise IT tasks — and every frontier model scores under 50%. Here's what the result actually says, the four failure modes it exposes, and how to rebuild your eval harness around it.
05/28/2026 · Model Evaluation · 9 min read